石墨烯区块链帐号体系的特点
这半年比较热门的EOS是石墨烯系列的最新区块链。(之前有BitShares, Steem, PeerPlay, 公信宝,yoyow) 石墨烯系列区块链有一个不同于比特币和以太坊的帐号体系,特点如下:
- 帐号和公私钥是绑定关系,操作语义通过帐号来指定,交易签名通过私钥来签,公钥验证。
- 每个帐号有多个角色的公私钥对,例如EOS包括owner和active。
- 新帐号必须通过区块链注册。
- 原生支持多重签名。
下面逐个说明。
帐号和公私钥绑定
在比特币区块链上,一个私钥对应拥有“花费该地址BTC余额”的权利。 而地址是公钥的一个变体。 一个钱包软件一般会管理很多组私钥和地址,需要收款时,可生成一个新的地址, 把这个新生成的地址直接发送给付款方即可,无需向区块链注册这个地址。 一个自然的设计就是,比特币的交易必须指定的收款方的地址,虽然那个地址人是没法记住的。
石墨烯系列则不同,多了一层显式的帐号,区块链使用者必须拥有帐号才能操作, 帐号是自己设定的便于记忆的名字,区块链的转帐交易内容是帐号到帐号, 与公钥(地址)或者私钥无关; 只有交易的签名需要使用相关帐号所关联的私钥来签, 区块链的p2p参与者(例如见证人或者超级节点)需要通过帐号关联的公钥来验证签名的有效性。
多个角色的公私钥对
有了帐号体系,是不是每一个帐号对应一个公私钥对呢?不是的, 一个帐号又分成了不同的角色,每个角色的权力不一样。owner角色拥有最大的权力, 可以进行任何操作; 而active角色则与转帐相关。在BitShares区块链上,有memo角色 的私钥并不参与签名,而是与对方的memo角色公钥一起,构成转帐私密备注的对称加密密钥来源 (搜索术语ECIES 或者 ECDH)。在Steem区块链上,还有一个特别的 posting角色,可以用于 发帖。
新帐号必须通过区块链注册
由于多了一层帐号,就涉及到帐号和公私钥对应关系的共识,解决的方法就是需要注册帐号, 通过已有的帐号向区块链广播一个”注册帐号”的交易来注册新帐号,这个交易的内容至少包括
- 新的帐号名
- 各个角色对应的公钥以及权重
除了注册帐号,还可以修改帐号,例如更换某个角色的公钥(需要使用owner角色的私钥来签名)。
原生支持多重签名
所谓多重签名,是指需要多个私钥共同签署确认一个交易,否则交易无法达成。帐号的每一个角色 都可以设定由多个公钥来共同管理:设定一个总的最低门限值和每个公钥的权重,签名有效的定义 是多个公钥的签名,并且这些公钥的权重之和大于该角色的最低门限值。举个例子,夫妻二人共同管理 一个帐号的active权限,那么可以一人生成一个公私钥对,注册/修改帐号时把该帐号的 active权限设为
- 总的门限值2
- 丈夫的公钥,权重为1
- 妻子的公钥,权重为1
这样总是需要双方同意才能动用帐号的资金。(当然这是一个简化的例子,由于owner权限更高级,需要把 owner权限也做相应的限制,避免通过owner权限绕过active的多签)
所谓原生支持,是指石墨烯系列区块链提供了多签功能的简单易用的API,直接使用即可。与之对应,如果比特币要支持多签, 则需要编写脚本,涉及复杂的编程逻辑; 如果以太坊要支持多签,需要通过编写智能合约来实现,而编写智能 合约本身是很难的,特别容易出现漏洞。前不久,著名的Parity钱包的一个多签合约漏洞就导致的大量ETH“锁死”。
原生支持多签这个特点,在使用好的情况下可以大大提高安全性:因为黑客需要拿到更多的私钥才能黑掉 一个帐号。
比特股钱包模式和账号模式的安全性差异
比特股官方钱包,目前支持两种模式,钱包模式和账号模式。老用户一般推荐新用户使用钱包模式,并告诉新用户,钱包模式更安全,那么,到底安全在哪呢?
首先,这两种模式下,密码和私钥仅仅涉及轻钱包、网页或者浏览器本身,不会通过网络泄露给第三方。在网络上传输的数据,都是区块链上公开的数据,谁都可以看。 轻钱包有锁定模式和解锁模式,锁定时,内存里面没有私钥,解锁时,内存里面有私钥。而当用户下单或者转账时,一定需要进入解锁模式,通过用户的私钥来对交易 签名,并广播出去。从这个意义上说,安全性没有什么区别。
在这个基础上,钱包模式一般来说确实更安全,因为钱包的备份文件是用户的主密码加密的,当需要转移机器、浏览器、轻钱包时,需要同时提供钱包备份文件和用户的主密码, 只要保存好自己的备份文件不外泄,一般不会被黑客破解拿到私钥。反之,账号模式下,没有钱包备份文件,所有的私钥都是账号和密码的hash函数,如果密码太弱,那么黑客 可以通过暴力攻击来碰撞得到用户的私钥,对高净值资产的账号,黑客尤其有这个动力。
但是事情也是有两面性的, 如果认为钱包模式安全,而设置一个弱密码,那么一旦备份文件落到他人之手,黑客破解起来反而更加容易;而考虑到账号模式本身的安全机制不足, 一般人会设置一个足够复杂的密码(新版官方钱包甚至要生成一个随机密码),其安全性就会比外泄备份文件的弱密码钱包模式要高得多。
总结一下见下表:
| 钱包模式 | 账号模式 | |
| 强密码 | 安全指数 4 | 安全指数 3 |
| 弱密码 | 安全指数 2 | 安全指数 1 |
这里的安全指数没有实际的量化意义,只是用来互相比较,指数越高越安全。最安全是钱包+强密码,这时候即使黑客拿到备份文件也无从下手;而账号模式如果有强密码,也是很安全的,无需担心什么; 反之,弱密码在两种模式下都不安全,只不过钱包模式下多了一个备份级别而已。 从易用性和安全性的平衡来说,账号模式+强密码,既安全,又易用,适合小白使用,老手也可以放心的使用。
注意,钓鱼网站、木马软件窃取用户的私密信息,不在本文讨论范围之内。
bitsharesjs库详解二:交易广播
上文 解析了ChainStore,本文继续,说一说如何利用用户的私钥来做交易广播。 如何搭建环境本文不再复述,请参考上文。
例子
运行
交易广播没有测试,只有一个例子文件,做的是转账,利用的是测试链。代码文件在这里 examples/transfer.js。运行方法
npm run example:transfer
不过一行不改,运行结果是这样的
> bitsharesjs@1.2.4 example:transfer /home/zzb/bitsharesjs
> babel-node examples/transfer
(node:21851) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1): Error: unexpected server response (200)
这个错误的根源在于,测试链的host改了,需要把第7行改成
7 | Apis.instance("wss://node.testnet.bitshares.eu/ws", true)
|
另外连接错误处理没有加(可帮助定位问题)。请读者自行处理。
仅仅修改第5行,重新运行例子,结果还是有问题的
> bitsharesjs@1.2.4 example:transfer /home/zzb/bitsharesjs
> babel-node examples/transfer
Connected to API node: wss://node.testnet.bitshares.eu/ws
connected to: Test network
synced and subscribed, chainstore ready
(node:22400) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1): timeout
一个timeout,让人好疑惑,出什么问题了呢?看了代码知道大约知道转账逻辑是从账号bitsharesjs向faucet账号转账0.1TEST币,用uptick看看bitsharesjs账号看看
uptick --node wss://node.testnet.bitshares.eu/ws info bitsharesjs
发现,没有那个账号!(关于那个timeout错误,实际上应该是没有账号错误,这个错误报得不准,与ChainStore的设计有关,读者可以查看ChainStore解析一文。)因此需要改第4行的私钥和第13行的账号,改成哪个呢?自己通过 测试链UI 注册一个最靠谱。注册完账号并且修改了之后,运行结果应该类似这样
> bitsharesjs@1.2.4 example:transfer /home/zzb/bitsharesjs
> babel-node examples/transfer
Connected to API node: wss://node.testnet.bitshares.eu/ws
connected to: Test network
synced and subscribed, chainstore ready
memo pub key: TEST8Sz5PMkSZftXi7qPL5XNeTMG9SQrxRPcsC4DdFRAvZr5qhgf6M
serialized transaction: { ref_block_num: 0,
ref_block_prefix: 0,
expiration: '1970-01-01T00:00:00',
operations: [ [ 0, [Object] ] ],
extensions: [],
signatures: [] }
然后在测试链UI上就可以发现转走了0TEST,解锁后可看到备注里面就是程序里面的。至于0TEST,实际上是0.1TEST,而代码上的量是10000,为什么呢?所有的资产都会设定一个最小单位,由小数点位数决定。例如测试链上TEST的小数点位数为5,而主链上BTS的小数点位数为5,人民币的小数点位数为4。 设定这个位数之后,所有的链上交易都用整数表示资产数量,其中1表示10的-n次方,n为资产的小数点位数。以测试链核心资产TEST来说,交易广播使用1表示1e-5,10000就是0.1了。整数的好处是没有浮点数加减法带来的误差,但对人来说并不直观,因此给用户显示,需要做一个转换。
代码解析
通过运行完成转账之后,解析一下例子代码:
- 第7~8行,websocket API初始化
- 第11行,ChainStore 初始化
- 13~22行,账号、资产、备注初始化
- 24~30行,从链上获取相关的账号和资产
- 32~69行,构造转账交易,签名,广播。
特别说明:
- FetchChain函数来自ChainStore,提供了一个直接向区块链查询的异步(Promise)接口,resolve时,返回的是Immutable的Map类型。
- new TransactionBuilder() 用于构造交易对象
- tr.add_type_operation填写交易对象的内容,包括类型和根据类型需要填写的字段
- tr.set_required_fees() 异步向区块链获取转账费用,
- tr.add_signer(priv_key, pub_key) 签名交易
- tr.broadcast() 向区块链广播交易
交易对象的填写
通过上文的代码解析,我们发现即使我们通过拷贝例子代码能够发起转账交易,我们也不知道怎么去下一个限价单,其他的步骤都好理解(或者可以直接抄),唯独 add_type_operation这个函数让人摸不着头脑。这时候需要看源代码,通过阅读 add_type_operation的实现代码,可以知道在 lib/serializer/src/operations.js 里面查找所有的操作和参数类型,例如转账参数从401行开始
401 402 403 404 405 406 407 408 409 | export const transfer = new Serializer(
"transfer",
{fee: asset,
from: protocol_id_type("account"),
to: protocol_id_type("account"),
amount: asset,
memo: optional(memo_data),
extensions: set(future_extensions)}
);
|
把这个参数和上面的 add_type_operation函数对比,是不是很清晰呢?如果要做挂单,显然就得看411行开始的定义了
411 412 413 414 415 416 417 418 419 420 | export const limit_order_create = new Serializer(
"limit_order_create",
{fee: asset,
seller: protocol_id_type("account"),
amount_to_sell: asset,
min_to_receive: asset,
expiration: time_point_sec,
fill_or_kill: bool,
extensions: set(future_extensions)}
);
|
需要注意的是:
- 区块链广播的买单和卖单都是卖单:用A资产买B资产,广播为卖出A资产,获得B资产。
- asset类型照例子处理
- time_point_sec 类型是时间戳,javascript里面构造一个Date对象即可。下层传输格式为 “%Y-%m-%dT%H:%M:%S”, 表示UTC时间,精确到秒。例如 2022-01-01T03:23:39 。
- fill_or_kill一般为false,表示等待限价单被对手吃。如果为true,表示不能成交的话立刻失效。
- extensions应该没啥用。(也许匿名交易需要,目前我不知道)
设计点评
关于交易部分,我觉得设计也不够人性化,比起python-bitshares来说易用性很差,需要程序员了解很多链上的细节。作为一个UI直接使用的中间库,明显抽象层次还是太低了。
思考
如何写一个程序,用你的私钥挂一个资产交易的限价单?欢迎留言。
比特股命令行神器:uptick
之前在介绍比特股开源代码时,漏掉了基于Python的uptick和其依赖库 python-bitshares,因为我确实没发现。最近试用了一下uptick, 我认为非常好用,用了之后,我不想用图形界面的钱包了。本文介绍一下uptick和其依赖的库。
作者:Fabian Schuh
这两个项目的作者是 Fabian Schuh,网名 xeroc, github地址: https://github.com/xeroc ,目前比特股理事会成员之一。个人感觉,他写的代码质量比较高。
项目简介
安装步骤
- 确保系统安装了Python3 (3.3 3.4 3.5 3.6应该都没问题)
- 确保系统安装了基于Python3的最新版本pip(9.0.1)
- 命令行: pip3 install uptick
- 命令行: pip3 install pycrypto (这一步理论上不需要,应该是某一个库依赖没写好的bug)
安装完成之后,首先需要设置API节点,否则默认是一个欧洲的节点,国内用的话很慢。国内尝试这两种
uptick set node wss://bit.btsabc.org/ws #比特帝国节点
uptick set node wss://bts.transwiser.com/ws #transwiser节点
当然,自己编译了并运行了全节点的话,就更快了:
uptick set node ws://127.0.0.1:8090/
这个节点设定同时影响uptick和python-bitshares库,或者说uptick直接修改和使用了库里面的配置。
uptick常用命令用法表
| 命令 | 含义 | 举例 |
|---|---|---|
| uptick | 获取帮助 | |
| uptick −−help | 获取帮助 | |
| uptick <COMMAND> −−help | 获取特定子命令的帮助 | uptick trades −−help |
| uptick addkey | 增加私钥到钱包,一般用active key用于交易 | |
| uptick listkeys | 列出钱包中所有私钥 | |
| uptick listaccounts | 列出钱包中所有账号 | |
| uptick trades <MARKET> | 查看某个市场的交易历史 | uptick trades BTS:CNY #最近,基于CNY的BTS成交情况 |
| uptick orderbook <MARKET> | 查看某个市场的当前限价单 | uptick orderbook BTS:CNY #现在市场上,基于CNY有多少BTS的买单和卖单 |
| uptick buy <AMOUNT> <ASSET> <PRICE> <BASE> | 提交买单 | uptick buy 2 BTS 0.4 CNY # 想用0.4CNY/BTS的价格购买2BTS |
| uptick configuration | 查看当前配置 | |
| uptick set <NAME> <VALUE> | 修改配置 | uptick set node ws://127.0.0.1:8090 # 设置API节点为本地重钱包 |
| uptick info | 获取各种信息 | |
| uptick info bitcrab | 获取账号bitcrab的相关信息 | |
| uptick info BTS | 获取核心资产BTS的相关信息 | |
| uptick history <account> | 获取某个账号的历史交易记录 | uptick hisotry bitcrab |
| uptick balance <account> | 获取某个账号的当前余额 | uptick balance os |
| uptick feeds <ASSET> | 获取某个智能资产的喂价信息 | uptick feeds CNY |
| uptick openorders <account> | 获取某个账号的未成交限价单 | uptick openorders a-bot |
给读者的思考
感谢阅读到这里的朋友,这么枯燥的技术细节您都读完了,能否思考以下问题呢?
- uptick/python-bitshares可以发起交易,账号存储在本地计算机,安全性如何?
- 如何利用uptick/python-bitshares发起交易?
- 如何利用uptick/python-bitshares发起转账?
虽然我的博客、公众号有一些读者,但很少有留言的,我希望读到这里的朋友留言,给出您的任何想法(不限上面的3个问题),谢谢!
bitsharesjs库详解一:ChainStore
bitshares开发入门:开源代码总览 介绍了比特股开源代码的总体情况,其中,bitsharesjs 位于UI层之下, bitsharesjs-ws 之上。本文尝试开一个系列之头:这个系列全部解析 bitsharesjs 代码。
bitsharesjs 库有三个主要模块,ECC, Chain和Serializer。ECC是关于椭圆曲线密码学的一些贴近钱包操作的库,Chain是关于链上数据获取和交易发起的,Serializer是Chain的工具支持,一般无需直接使用。 本文阐述Chain中的一个类: ChainStore。ChainStore的功能是链上数据的获取和缓存。本文提到的代码,如无特别说明,均以bitsharesjs的根目录为相对目录的起点。
环境准备
- 安装Nodejs到本地,建议安装当前的LTS版本,本文写作时,为 6.10.3 (如果已经安装请跳过这一步)
- 克隆代码到本地 ( 命令行下执行:git clone https://github.com/bitshares/bitsharesjs.git )
- 进入 bitsharesjs目录, npm install
注意:本系列文章依赖bitsharesjs的git版本 bdda47c2250b9b9ecf92d682849c7b5b1efae90f ,请确保一致,否则可能会造成理解偏差,尤其涉及代码行号。
从测试代码说起
测试代码文件: test/chain/ChainStore.js
测试方法,命令行键入
npm run test:chain
注意这个测试会测试 test/chain目录下的所有测试文件, ChainStore只是一个。如果没有本地重钱包,你会发现ChainStore会测试失败。下文教你如何修改代码来做测试。
背景说明:测试使用的是 mocha BDD测试框架 ,并且(整个项目)使用了 babel转码。
第3行
3 | import { FetchChain, ChainStore } from "../../lib";
|
导入了ChainStore。
第9-15行
9 10 11 12 13 14 15 | before(function() {
/* use wss://bitshares.openledger.info/ws if no local node is available */
return Apis.instance("ws://127.0.0.1:8090", true).init_promise.then(function (result) {
coreAsset = result[0].network.core_asset;
ChainStore.init();
});
});
|
所有测试用例运行之前需要做初始化:先连接上全节点,测试代码使用的是本地节点,第10行注释说得明白,如果没有本地节点,那么就使用公网节点,例如openleger的。国内测试,建议改成帝国的: wss://bit.btsabc.org/ws 。 另外第13行有个 bug ,需要在前面加上 return,否则默认 return undefined,整个函数就会resolve掉,可能导致ChainStore没有初始化完成就执行测试用例,会出错的。修改后的代码应该是这个样子:
9 10 11 12 13 14 15 | before(function() {
/* use wss://bitshares.openledger.info/ws if no local node is available */
return Apis.instance("wss://bit.btsabc.org/ws", true).init_promise.then(function (result) {
coreAsset = result[0].network.core_asset;
return ChainStore.init();
});
});
|
这样就可以测试了。但是,读者会发现,测试用例不见得全部pass。这里面有另一个BUG,下文详解。
init函数
当底层Api(bitsharesjs-ws提供的Apis)初始化OK时,必须调用ChainStore的init函数初始化,正如第13行所做的那样。
首先, ChainStore这个变量,容易混淆,这个是从 lib/chain/src/ChainStore.js这个文件导入的,而这个文件定义了一个ChainStore类,但本身导出的确实ChainStore类的一个全局Singleton
1352 | let chain_store = new ChainStore();
|
1352行生成了ChainStore类的一个实例。
1407 | export default chain_store;
|
1407行导出这个实例。
因此测试代码导入的ChainStore,是ChainStore.js文件中定义的ChainStore类的一个全局实例。这句话很绕口,多读几遍。
回到init函数,该函数返回一个promise,resolve的时候初始化成功。其他函数必须在init函数返回resolve之后调用。正因为这个特点,才有了上文所述第13行的少return的BUG。
4个测试用例的所调用的两个函数
4个测试用例实际上主要调用了ChainStore(Singleton)的两个函数:
- getAsset
- subscribe
其中 getAsset是 getObject的封装,表示获取资产。而getObject是一般的“获取对象”函数,而“对象”是bitshares区块链的核心数据。对象的id是3个整数, a.b.c。其中:
- a表示空间,两个取值:1表示协议对象,这些对象会在websocket和p2p网络上传输;2表示实现对象,用于节点本地存储,可认为是共识数据的衍生数据。
- b表示类别,协议对象和实现对象都有十多类不同数据。
- c表示实例,不同类型数据的实例编号。
例如
2.1.0 表示动态全局相关数据,例如一个抓取的实例:
{ participation: 100, recently_missed_count: 0, accounts_registered_this_interval: 22, next_maintenance_time: '2017-05-24T04:00:00', dynamic_flags: 0, witness_budget: 76200000, head_block_id: '0100685ba0b1d1902e8ccea5e0eac2172f679873', time: '2017-05-24T03:47:27', recent_slots_filled: '340282366920938463463374607431768211455', current_witness: '1.6.72', current_aslot: 16909777, head_block_number: 16803931, id: '2.1.0', last_irreversible_block_num: 16803912, last_budget_time: '2017-05-24T03:00:00' }
1.3.x 表示各种类型的资产
- 1.3.0 核心资产BTS
- 1.3.113 锚定资产bitCNY
- 1.2.x 表示各个账号
- 1.2.0 理事会多重签名账号
- 1.2.121 理事会成员巨蟹的账号 bitcrab
- 1.2.12376 理事会成员abit的账号 abit
- 1.7.x 表示用户提交的限价单
- 1.8.x 表示call order(我还真没搞清楚是什么意思,请留言)
- 1.11.x 表示用户相关的活动历史,提交限价单,取消限价单,转账给别人,收到转账等等
常用对象列表 可参看大部分的对象类型。
好,回到getObject函数,这个函数总是立即返回的,返回值有三种情况:
- 返回 Map 类型 的对象,表示缓存中有了这个对象
- 返回null,表示没有这个Object(id无效)
- 返回undefined,表示正在查询API节点,需要以后重新调用
getAsset是getObject的封装,因此返回值同样遵守这个约定。由于getObject立即返回,而调用的时候如果返回undefined,怎么等呢?用 subscribe函数。 subscribe函数是通用的事件监听函数, 当 websocket连接之后,任何从API节点的事件,都会触发所有的监听者(subscriber)。
这个设计本身是否足够好?我认为不够好,因为subscribe会导致大量的无效监听,而getObject和subscribe的联合使用,从理论上说不一定能达到预期的效果: 因为监听者无法区分事件本身,而JS的异步特性会导致不确定性。从测试代码来说,4个测试用例并行执行,和webSocket的事件触发次序的不确定性,会导致subscribe里面的getAsset函数不一定得到想要的结果。如果改写其中的一个测试用例,设成it.only (忽略其他的测试用例),目前我的测试结果是总可以通过的,但从理论上,我仍然不相信这种单个测试用例的测试方法:万一监听到一个不相关的事件呢?从这个意义上来说,测试代码还不好写得正确,现有测试代码怎么改成逻辑自洽的还很难。
另外,就ChainStore来说,测试代码的覆盖也完全不够,下面看看例子代码。
例子代码
例子代码在这里: examples/chainstore.js
运行
npm run example:chainStore
可以发现一直打印ChainStore的全局动态对象 2.1.0的当前值。
例子代码比测试代码简单,用到的函数是getObject,运行例子代码会对上文提到的无效监听设计有直观的认识。
例子代码的修改
例子代码太简单了,只获得一个动态全局对象,不利于理解很多其他的概念。我通过阅读ChainSore.js的源代码,改了下,可以获得巨蟹的账号情况,注意其中的资产和操作历史:
import {Apis} from "bitsharesjs-ws";
import {ChainStore} from "../lib";
Apis.instance("wss://bitshares.openledger.info/ws", true).init_promise.then((res) => {
console.log("connected to:", res[0].network);
ChainStore.init().then(() => {
ChainStore.subscribe(getBitcrabAccount);
});
});
function getBitcrabAccount() {
var bitcrab = ChainStore.getAccount('bitcrab');
if( bitcrab) {
var bitcrabObj = bitcrab.toJS();
console.log('my account', bitcrabObj);
var balances = bitcrabObj.balances;
if( balances ){
for (var assetId in balances ){
var asset = ChainStore.getAsset(assetId);
if( asset ){
var assetObj = asset.toJS();
console.log('asset:', assetId, assetObj);
if( assetObj.dynamic_asset_data_id) {
var dynamicAsset = ChainStore.getObject(assetObj.dynamic_asset_data_id);
if( dynamicAsset ){
var dynamicAssetObj = dynamicAsset.toJS();
console.log('asset dynamic:', assetId, dynamicAssetObj);
}
}
}
// var balance =;
var balance = ChainStore.getObject( balances[assetId]);
console.log('asset balance:', assetId, balance.toJS());
}
}
var history = bitcrabObj.history;
if( history ){
history.forEach( function(h){
console.log('history', h);
console.log('opration', h.op);
});
}
}
}
运行修改的例子代码会不停的输出巨蟹的账号相关信息。关于操作历史,最重要的是什么操作?op的数据结构是二元组,第一个数表示操作类型,第二个对象表示具体的数据。而操作类型可以在 lib/chain/src/ChainTypes.js 里面找到,代码我就不贴了。
总结
关于ChainStore的代码解读就这些了,这个过程我总结下来:
- ChainStore的接口设计不算特别合理。怎么样才更好呢?是一个值得思考的问题。
- 业务逻辑和代码需要结合起来,比如a.b.c对象的意义,操作类型的意义。
- ChainStore测试和例子的质量不高,大体可判断,bitsharesjs总体的代码质量有待改进,如果对质量要求高,可以考虑直接使用钱包和节点的 JSON RPC API。
源码解析:bitshares-ui的钱包和帐号管理
本文试图从一个宏观架构的层面解析bitshares-ui这个应用中的钱包和账号管理,为作者接下来实现一个通用的私钥管理器做准备。
用到的库和标准
alt
alt 是 Flux架构 的轻量级和紧凑的实现,支持ES6语法。
Flux架构是Facebook开源的一种用户界面程序架构,特点是单向数据流,核心组件包括 Actions 、 Stores 、Views 和 Dispatcher 。其中
- Actions表示动作,可能带参数,一般由Views根据用户操作,通过dispatcher广播出来
- Stores存储应用的数据,监听并响应dispatcher广播的、与自身相关的Actions,修改自身的数据,当修改时,广播一个 change事件
- Views代表用户界面,从Stores拿数据,展示给用户,并在stores的change事件发生时,重新获取数据刷新界面
Flux架构的好处:
- 相对于MVC来说,去掉了Controller,强化了数据层;
- Stores作为各个View的统一数据来源,为各个View提供了同步的数据;
- 对数据的修改不是直接的,分离了用户操作意图和实际的数据修改,更容易调试。
下图是一个Facebook提供的直观的Flux架构图。
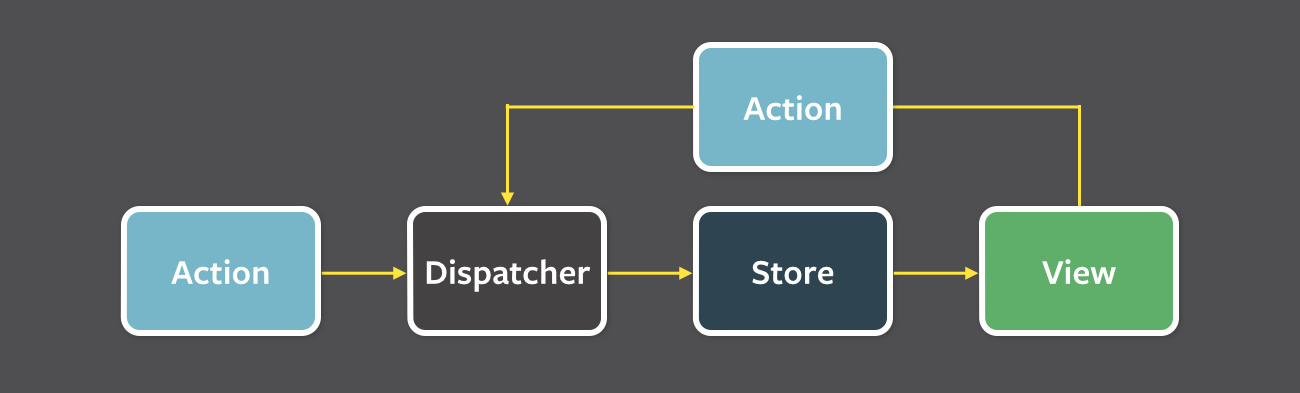
alt库提供了Flux架构所需要的Actions、Stores和dispatcher API。
indexedDB
indexedDB 是一个W3C建议标准,用于在浏览器中存储结构化的对象数据库,是过时标准 WebSql 的替代。
indexedDB的存储分为以下几个层次:
- 域,浏览器为不同的域(不同的应用)存储不同的数据库集合,避免跨域数据盗用
- 数据库,同一个域下面可以有不同名称的数据库,每个数据库有相对独立的应用目的
- 对象商店(Object Stores),每一个数据库可以包含多个对象商店,对象商店可类比Sql数据库中的表
- 对象,对象商店中的一个实体,可类比Sql数据库中的行
对象商店可以有不同的形式,键值对形式和对象集合形式。
indexedDBShim
由于 IndxedDB标准比较新,各个浏览器实现有差异,有些还有BUG,因此为了更好的兼容性,indexedDBShim 项目被开发出来,为各种javascript环境(不同的浏览器甚至Nodejs)提供一致的indexedDB API。 下文引用github官网的项目说明
Use a single, indexable, offline storage API across all desktop and mobile browsers and Node.js.
Even if a browser natively supports IndexedDB, you may still want to use this shim. Some native
IndexedDB implementations are very buggy. Others are missing certain features. There are also
many minor inconsistencies between different browser implementations of IndexedDB, such as how
errors are handled, how transaction timing works, how records are sorted, how cursors behave,
etc. Using this shim will ensure consistent behavior across all browsers.
indexedDBShim在使用的时候,可以强制在支持indexedDB的浏览器也用shim(websql模拟),好处是啥?也许这样更稳定更不容易出错,因为websql的实现各个浏览器都是成熟的和一致的(sqlite)。
相关文件
本文提到的文件,都以 bitshares-ui 项目的根目录为相对目录的起点。 下文给出简表。
| 文件名 | 说明 |
|---|---|
| web/app/alt-instance.js | alt全局Singleton |
| web/app/idb-instance.js | indexeddb实例封装 |
| web/app/stores/BaseStore.js | 基于alt库store的其他store的基类,一种混合编程范式 |
| web/app/stores/WalletDb.js | 钱包Store |
| web/app/stores/PrivateKeyStore.js | 私钥Store |
| web/app/stores/AccountStore.js | 账号Store |
| web/app/stores/tcomb_structs.js | 各种数据结构定义 |
存储的层次
存储的层次从最底层(离用于使用最远),到最上层,可分为钱包备份层,Web浏览器中的数据库层和内存层。
钱包备份层
钱包备份层是备份在硬盘上的钱包文件,可以跨浏览器,跨终端导入导出使用。钱包备份文件需要使用用户的主密钥解密才能导入,解密方法,请看 使用NODEJS解密bitshares网页钱包备份文件 。
Web浏览器中的数据库存储
如果在某个网页钱包(例如 比特帝国 和 Openledger )上注册或者恢复了钱包,那么钱包中的数据会存储在浏览器的数据库中,操作的接口是 indexedDB,而由于bitshares-ui的实现强制使用了 indexedDBshim的shim模拟,实际上这些数据存储在Websql里面。 当钱包应用打开时,会读取一些钱包中的账号数据,与区块链API比对,可拿到用户的名称和余额等等信息。而当增加账号或者修改账号的公钥时,会通过上文所述Flux架构及其alt实现,最终修改数据库中的信息。私钥这种敏感信息在数据库中永远是加密状态。
Web浏览器的运行内存
网页钱包的运行数据会在内存中体现,表现形式是Flux架构的各种Store。
钱包相关的数据和加密方法
与钱包相关的数据,从web浏览器的数据库层来解析比较好理解。在这一层,包括三个对象商店,分别是 wallet, privatekey和 link_accounts。
wallet
wallet商店一般包含一个对象,表示用户的钱包的基本信息
wallet的结构,可参考文件 web/app/stores/tcom_structs.js 第27到41行
27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | let WalletTcomb = t.struct({
public_name: t.Str,
created: t.Dat,
last_modified: t.Dat,
backup_date: t.maybe(t.Dat),
password_pubkey: t.Str,
encryption_key: t.Str,
encrypted_brainkey: t.maybe(t.Str),
brainkey_pubkey: t.Str,
brainkey_sequence: t.Num,
brainkey_backup_date: t.maybe(t.Dat),
deposit_keys: t.maybe(t.Obj),
// password_checksum: t.Str,
chain_id: t.Str
}, "WalletTcomb");
|
各字段意义如下表:
| 字段名称 | 意义 |
|---|---|
| public_name | 钱包名字,一般为default,用户可管理多个钱包 |
| created | 钱包创建时间 |
| last_modified | 最后修改时间 |
| backup_date | 备份时间 |
| password_pubkey | 主密钥生成的ECC公私钥对中的公钥 |
| encryption_key | 由主密钥加密的,用于加密私钥的密钥(AES密钥) |
| encrypted_brainkey | 加密的脑钱包种子,用于生成ECC公私钥对(HD) |
| brainkey_pubkey | 脑钱包种子生成的ECC公钥(与HD无关) |
| brainkey_sequence | brainkey序号,下一个密钥对从这里算 |
| brainkey_backup_date | brainkey备份时间 |
| deposit_keys | 不清楚 |
| chain_id | 石墨烯区块链ID,可区分主链测试链 |
注:HD表示Hierarchical Deterministic, 从一个种子开始,可序列化的、确定性的生成多个私钥,可参考 这篇文章 。 一般脑钱包(brain wallet)可以用例如12个随机英文单词作为种子,因此brainkey就指种子本身。
privatekey
privatekey表示用户的各种私钥:
- owner key, 账号拥有者私钥,可以通过这个私钥修改其他密钥设置
- active key, 活动私钥,可以通过这个私钥签署交易广播
- memo key, 备注私钥,可以解密交易对手发过来的备注
privatekey结构,参考同一个源文件的第43-50行:
43 44 45 46 47 48 49 50 | let PrivateKeyTcomb = t.struct({
id: t.maybe(t.Num),
pubkey: t.Str,
label: t.maybe(t.Str),
import_account_names: t.maybe(t.Arr),
brainkey_sequence: t.maybe(t.Num),
encrypted_key: t.Str
}, "PrivateKeyTcomb");
|
最有用就是2个字段:
- pubkey,公钥,
- encrypted_key, 加密的私钥
encrypted_key的加密密码在哪里?答案是加密存储在wallet对象的 encryption_key字段里(见上表),而后者的加密密码是用户的主密钥。
另外:
- brainkey_sequence 表示这个私钥的生成序列号,wallet中 brainkey_sequence为所有privatekey中最大brainkey_sequence + 1。
linked_accounts
linked_accounts表示用户的账号信息,主要包含两个字段,账号名称和区块链id。
钱包锁定和解锁
在privatekey对象中,存在一个encrypted_key,需要解密才能使用。当用户解锁钱包时,wallet对象中的encryption_key被解密,并保留在内存一段时间。 通过解密后的密码,可以解密出私钥,进而进行签名操作。当钱包锁定时,wallet对象中没有明文的密码,无法解密出私钥进行计算。
小结
本文讨论了bitshares-ui源代码中关于钱包和账号的管理方法,希望对本文读者有所帮助。
椭圆曲线密码学相关概念与开源实现
引子
在阅读并尝试使用椭圆曲线加密相关代码时,很多时候需要对底层的概念有所了解,而不仅仅限于使用。例如前文 NODEJS中椭圆曲线签名和验证 就仅仅限于加密货币领域和NODEJS。本文尝试对椭圆曲线密码学的相关概念做一个梳理,这样能够帮助读者以及我自己更好的去挑选和使用相关的开源代码。
概念与缩写
简表如下:
| 缩写 | 英文全名 | 中文翻译 |
|---|---|---|
| EC | Elliptic Curve | 椭圆曲线 |
| ECC | Elliptic Curve Cryptogphay | 椭圆曲线密码学 |
| ECDSA | Elliptic Curve Digital Signature Algorithm | 椭圆曲线数字签名算法 |
| DH | Diffie-Hellman Key Exchange | Diffie-Hellman密钥交换 |
| ECDH | Elliptic Curve Diffie-Hellman Key Exchange | 椭圆曲线Diffie-Hellman密钥交换 |
| IES | Integrated Encryption Schema | 集成加密框架 |
| ECIES | Elliptic Curve Integrated Encryption Schema | 椭圆曲线集成加密框架 |
| KDF | Key Derivation Function | 密钥(私钥)生成函数 |
说明与参考:
EC就是椭圆曲线,是一个数学上的概念,注意并不是椭圆。ECC是基于椭圆曲线的公私钥密码体系,ECDSA就是这个密码体系下的签名(与验证)算法。DH是两个人名字首字母缩写,因为他们首次发明了在敌意网络环境下安全的利用公私钥加密算法协商出对称加密密钥的方法, 可参考 这个维基页面 。ECDH就是利用椭圆曲线公私钥密码体系来交换对称加密密钥的方法。IES用于文件或者磁盘加密,是一种混合公私钥密码和对称加密方法的块加密系统, 可参考 另一个维基页面 ,其原理与DH密码交换相同。KDF是指一个生成密钥(私钥)的函数。
关于ECC和ECDH,可以看这两个Youtube视频:
Elliptic Curve Cryptography Overview 以及 Elliptic Curve Cryptography & Diffie-Hellman 。
不愿意或者没有能力看视频的朋友,我给出两张截图。
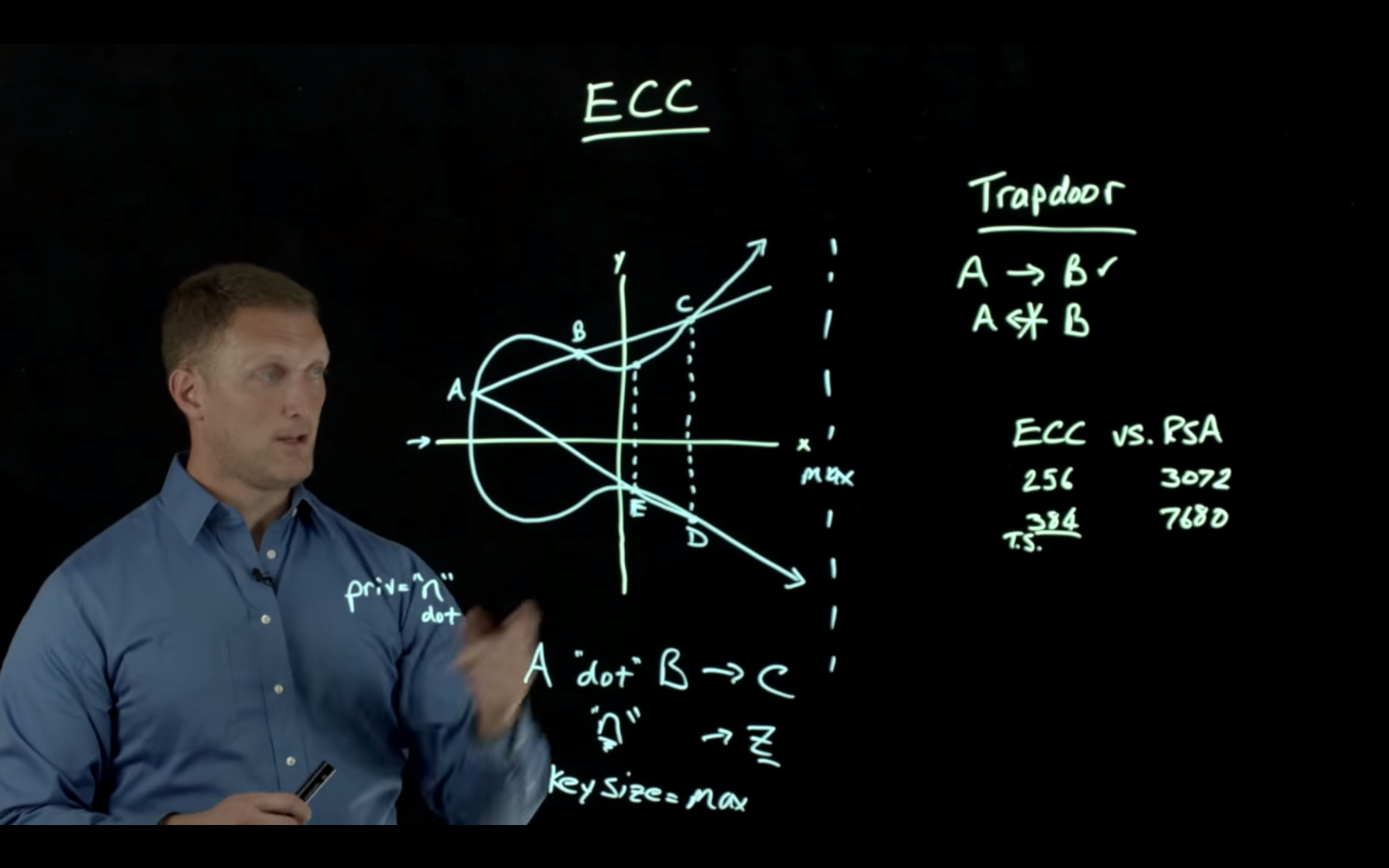
这张图很形象的描述了ECC的数学模型和加密安全性,以及什么是私钥,以及密钥长度。

这张图说明在ECDH密码交换时,我们需要给定哪些域参数。
参数与标准
椭圆曲线本身是数学模型,而曲线的参数在使用的时候需要公开并且一致,否则多方无法参与(张三用A曲线而李四用B曲线是没法对话的)。选择什么样的参数才能安全又高效呢?
SECG 组织(Standards for Efficient Cryptography Group)给出了相关标准,包括
- SEC-1 椭圆曲线密码学
- SEC-2 椭圆曲线密码学推荐的域参数
- SEC-4 暂时忽略,我也不知道是啥
SEC-2里面给出了各种参数,并且每一组参数给出了一个命名,这样在使用的时候,通过名称就确定了参数。例如secp256k1就是比特币率先采用的一组参数,在加密货币领域十分流行。
开源实现
openssl
openssl 是著名的C库和命令行工具箱,实现了各种密码学的函数,包括椭圆曲线。 参考 openssl中ECC命令行操作 可以了解到Openssl命令行 的ECC密钥管理和ECDH以及ECDSA算法的使用。本文列出一些,读者可以照做,加深认识。需要注意的是,Mac OS上自带openssl太旧,需要使用 Homebrew 安装的版本。
openssl genpkey -genparam -algorithm ec -pkeyopt ec_paramgen_curve:secp256k1
生成了PEM格式的椭圆曲线域参数文件到标准输出。
openssl genpkey -genparam -algorithm ec -pkeyopt ec_paramgen_curve:secp256k1 -out secp256k1.param
生成了PEM格式的椭圆曲线域参数文件到 secp256k1.param 文件里面。
openssl genpkey -paramfile secp256k1.param -out my.key
利用参数文件生成PEM格式(明文)的私钥文件。
openssl genpkey -aes256 -paramfile secp256k1.param -out my.key
利用参数文件生成AES加密的私钥文件,即使文件泄露,黑客没有密码也无法使用私钥。
openssl pkey -in my.key -text -noout
查看密钥。
openssl dgst -sign my.key -sha512 file-to-be-signed -out signature-file
生成签名文件。
openssl ec -in my.key -pubout -out pub.pem
私钥转公钥文件。
openssl dgst -verify pub.pem -sha512 -signature signature-file file-to-be-signed
公钥验证签名。
eccrypto
eccrypto 是一个Javascript上的ECC库,特点如下:
- 同时支持浏览器和Nodejs, API相同。
- 支持哪种椭圆曲线? secp256k1。
- 如果浏览器支持,使用W3C正在制定WebCrypto标准。
- 如果可能,使用Nodejs内置的Crypto模块。
CryptoCoinJS
CryptoCoinJS 是一个项目组,创建了多个用于加密货币的Javascript项目,其中的 Ecurve 项目是一个通用的ECC库,支持各种参数的椭圆曲线。
以太坊简介
在加密货币和区块链领域,以太坊(Ethereum)是目前除比特币之外最有影响力的公有链(基本上可以说没有之一)。以太坊之所以著名,笔者认为与两个主要因素有关:
- 首次实现图灵完备的智能合约平台
- 以太坊创始人Vitalik Buterin的技术能力和社区运营能力都是一流的
什么是智能合约?简而言之,就是机器自动执行的法律合同。一般意义法律合同的执行,是由合同参与方手动来操作的,当遇到对合同文本理解不一致或者恶意抵赖的情况,当事人可 通过法院来仲裁甚至强制执行。而智能合约,就是用计算机代码编写的合同,如果代码没有缺陷,当外部条件成立(例如时间到了)时,其执行是自动的,不存在恶意抵赖的情况。因此, 智能合约和传统合同的主要区别有两点:
- 传统合同采用中文或英语等人类语言,存在二义性;智能合约采用计算机编程语言,没有二义性。
- 传统合同的执行靠参与方自觉以及法院仲裁,是人来做;智能合约由计算机自动执行,人只需要在适当触发执行条件即可。
关于以太坊的编程学习,中文方面有一个 以太坊爱好者网站 。如果英文不错,可以到 Udemy 去刷视频教程, 其中 EthereumDeveloper 课程还挺好的,内容丰富,如果碰到打折,10美元就可以购买。
最后简单介绍一下以太坊钱包、帐号和比特股钱包、帐号的不同。比特股中,钱包和帐号与现实世界的钱包和帐号很类似,钱包相当于现实世界的钱包,帐号相当于现实世界的银行卡帐号。一个钱包里面可以包含 多个银行卡:对应比特股来说,一个钱包里面可以有多个帐号。以太坊的钱包有两种意思,一种与比特股和现实世界类似,指管理帐号的存储介质和程序;另一种,却表示一种帐号类型,以太坊有两种帐号 类型,一种叫外部帐号,一种叫合约帐号。外部帐号是人控制的帐号,可以转帐和触发合约帐号执行合约;合约帐号就智能合约的载体帐号,包含程序字节码和存储状态,可在特定条件下执行合约。合约帐号 也叫钱包帐号。因此,以太坊中的钱包就有两种不同的意思,需要根据上下文来区分。
关于以太坊的介绍到此结束,感谢看到这里的朋友!
使用NODEJS解密bitshares网页钱包备份文件
有一位我的博客读者,问了我一个问题,比特股钱包的密码忘了,想写一段程序暴力破解,可是没有找到相关的代码和调用方法。我带着这个问题,去代码里面找了找,写了一段 简单的程序 ,本文阐述一下这段程序的逻辑。
其实主要的逻辑在19~61行,也就是函数decryptWalletBackup,是从bitshares-ui拷贝出来的(请看18行注释)。这个函数接受两个参数,backup_wif和backup_buffer。前者是wif格式的私钥(参考 这篇博文 ), 后者是钱包备份文件(.bin)的内容。backup_wif怎么来的呢?参考第71行,是密码的确定性函数。
decryptWalletBackup函数的调用在74行,如果密码正确,75行console.log会被调用,否则,76行console.error会被调用。如果用nodejs来做暴力破解,不断的修改密码看看decryptWalletBackup这个函数是否能resolve promise即可。
其实,代码解析到这里,也许读者朋友会觉得很无趣,因为这个解析显得有些简单了。那么,难在什么地方呢?一般来说,知识不难,获取知识并应用的过程比较难。授人以鱼,不如授人以渔 : 具体来说本文尝试回答两个主要问题,并在阐述第二个主要问题时提出两个小问题和我的思考。
第一个问题,如何从开源代码中快速准确找到需要的功能?这其实是一个代码阅读的方法问题。我的回答: 要从代码中重建作者的逻辑框架,并进行层次合理的抽象 。就一个特定问题来说,当一个人不知道从哪里去找相关代码的时候,需要整体理解代码的框架,然后针对性的阅读感兴趣的部分,并且按照自己的理解去做局部测试。就好比玩乐高积木, 别人搭好的建筑,我们需要局部借鉴并且建一个新的,做法就是恰好把需要的局部拆下来,再重新搭。比如本文讨论的问题,要本地暴力破解,想知道代码在哪,那么首先得大体理解 bitshares-ui 代码整体的结构:
- 知道这是一个基于React(package.json里面的依赖,以及源代码里面有很多jsx文件)和Webpack(package.json里面的各种快捷命令)的项目
- 下层依赖什么库?从 package.json 里面看
- bitshares-ui代码结构?看子目录,需要大体理解 React的组件编程方法论
- 从顶层组件开始,大体理解代码和使用网页钱包的关系
从这个角度出发,根据目标分解,逐步的去找,就能找到想要的任何组件以及其调用的任何库的方法。
第二个问题,如何控制抽象级别并且避免陷入细节?这个问题比第一个问题更具体一些,需要时常锻炼。回答第一个问题时说到的“合理的抽象”,也是一个意思。与盲人摸象一样,其实如果每个盲人关注大象的每一个局部,只要目标允许,就是合理的,关键需要理解自己所关注的局部和整个大象的关系,不把局部代替为整体就好。 研究代码,并不需要一下子把所有的部分都搞明白才能修改或者使用局部代码,从代码整体的结构往下看,一级一级找下去,找到能满足目标的可能解决方案,就放手去验证,并通过实际操作反馈,调整自己的逻辑假设,重新验证,这样反复迭代几次,可迅速完成目标。经常训练的话,迭代次数可为个位数。其实,我本人并没怎么学过和使用过 React,但并不妨碍 我从总体上理解React的组件编程模型,也不妨碍我从大型React项目(bitshares-ui)中找到感兴趣的部分(网页钱包备份解密方法)并加以利用。关注目标,通过抽象来隐藏细节,理清组件之间的接口关系,是关键。我这里列举2个小问题并给出我的思考,也许读者就更好理解了。
小问题1:如何使用其他编程语言(C++/Python/Go)来解密网页钱包?由于这个问题的上下文与本文讨论的主要问题不一样,因此需要的知识也不一样了。要自己实现的话,需要从bitsharesjs库内部,理解网页钱包的格式、压缩和加密方法,并从其他编程语言将这些逻辑重组。问题是,如果没有这样一个目标,就无需理解这么多, 直接理解前文的接口调用即可。
小问题2:网页钱包备份的格式怎么样的?这个问题可从问题1派生。我的答案是,我不甚了解,但如果有需要的话,可以分N层去解释。可以肯定的是,网页钱包的前33个字节为一个临时公钥的二进制形式,后面是AES加密存储的内容。在这个AES加密内容中,必定有一部分与前面的公钥相关,使得解密过程可以直接判断密码是否正确。这个结论是我从 bitshares-ui中的那个文件中的代码推导出来的,但是更细节的结构,例如解密过程怎么验证密码的正确性,就得研究bitsharesjs库中 AES.decrypt_with_checksum的实现了。
好,本文到此结束,感谢看到这里的朋友。如果你有任何问题,欢迎联系我,也许我能帮你解决一个问题,并同时分享些心得给更多的朋友。
身份认证概念原型发布,目前的反馈和我的思考
上文 讨论了基于任意加密货币的用户身份认证设计思路,目前我已经弄出了一个概念原型, 部署在 heroku 上,有Steem账号或者比特股账号的可以去尝试下。代码是开源的,有兴趣的读者可以查看 multi-currency-login 和 WifSign 。 我在各个渠道发布了这一消息,已经收到一些朋友们的关注和反馈,本文做个总结并继续讨论身份验证这个话题。感谢 abit(@steem), Alex(@yoyow)以及Patrick(@qtum)给我提供的非常有价值的反馈,感谢所有支持我这个想法的朋友!
反馈1: 在第二步签名的时候,用户不相信即将去往的 签名的网页 ,在这个上面填写私钥或者密码,万一被恶意拿走怎么办?
我的思考,这当然是一个最大的问题,同时也蕴藏着很大的机会。从技术角度说,我目前能提供的信任是:
- 代码是 开源 的,用户可以自己部署一个类似的网页
我不能提供的信任是:
- 开源的代码并没有经过严肃的安全审计,也许存在恶意代码或者漏洞
- 即使提供了严肃的安全审计,也没法保证部署在githubpages上的网页是安全可靠的。
另外还有非技术层面的信任问题,本文不讨论。
反馈2: 这个方法不能有效的避免中间人攻击问题。
我的思考,不妨假设用户Alice访问一个论坛采用了现在这个原型的认证方法,中间人攻击分为如下两个方面:
客户身份冒用, 即有一个Bob夹在Alice和论坛服务器中间,当Alice的身份认证通过后,冒用Alice的身份。我认为这是最重要的安全隐患,也是一个可以考虑的技术改进之处。从网络层次上来说,我这个身份认证系统处于 应用层面,而成熟的https(SSL)处于传输层,SSL技术本身是可以解决中间人攻击的。但是,大多数用户使用的https(SSL)是用来防止服务器身份冒用的,只有部署了客户端证书的https才能避免客户端身份冒用,如果这个方法 能够与https客户端证书相结合,下沉到传输层,那么能够有效的解决中间人攻击问题,也更有意义;但是如果不能做到这一点,应用层的身份认证仍然有其自身的价值。
服务器身份冒用,即有一个Bob夹在Alice和论坛服务器中间,对Alice冒充服务器。这个问题也分为传输层和应用层,传输层https已经解决了这个问题(除了CA本身是一个问题)。应用层的话可以用类似的方法来验证服务器, 上文 已经描述过,只不过目前的原型里没有,我倾向于认为这个功能不重要。
总之,中间人攻击问题重要,但我认为,解决这个问题犹如锦上添花,不是雪中送炭。
反馈3:易用性问题。可以弄浏览器插件啥的。
我的思考,完全同意。易用性是普通用户愿不愿意去使用这个方法的关键,也是论坛愿不愿意部署这种方法的关键。这个问题和第1个信任问题在一起,构成了我这个思路能否继续顺利实施的关键。我基于现有的技术,对这两个问题有了一个 新的思考:开发独立的,经过安全审计的第三方授权应用(类似目前概念原型中的WifSign)。这个应用完成如下功能:
- 内部加密存储各种私钥。
- 用户通过好记的名字管理这些私钥。
- 响应用户的签名请求,对挑战数据进行签名并返回签名结果。流程类似OAuth,但没有第三方服务器。
因为这个经过安全审计的第三方授权应用只有一份,并且运行在用户自己的计算机上,因此一旦做出来并且成功推广,可以让不止一个网站或者论坛使用,具有以下价值:
- 用户避免到处注册;
- 用户无需借助大公司的平台(QQ、微信、微博、Google、Facebook)来认证自己;
- 最大程度避免私钥泄露。
好,本文到此结束。谢谢看到这里的朋友,如果你有任何意见和建议,欢迎留言。如果无法留言,欢迎发邮件给我。当然,欢迎转发本文链接!